1.熵编码
1.1 研究背景
数据压缩技术的理论基础就是信息论。信息论中的信源编码理论解决的主要问题:
(1)数据压缩的理论极限;
(2)数据压缩的基本途径。
根据信息论的原理,可以找到最佳数据压缩编码的方法。数据压缩的理论极限是信息熵。信息熵为信源的平均信息量(不确定性的度量)。
如果要求编码过程中不丢失信息量,即要求保存信息熵,这种信息保持编码叫熵编码,是根据消息出现概率的分布特性而进行的,是无损数据压缩编码。因此,熵编码即编码过程中按熵原理不丢失任何信息的编码。
1.2 常见的熵编码
在视频编码中,熵编码把一系列用来表示视频序列的元素符号转变为一个用来传输或是存储的压缩码流。输入的符号可能包括量化后的变换系数,运动向量,头信息(宏块头,图象头,序列的头等)以及附加信息(对于正确解码来说重要的标记位信息)。
常见的熵编码有:
香农(Shannon)编码
哈夫曼(Huffman)编码
算术编码(arithmetic coding)
行程编码 (RLE)
基于上下文的自适应变长编码(CAVLC)
基于上下文的自适应二进制算术编码(CABAC)
熵编码一个很重要的应用领域就是图像压缩。
下面是JPEG的编码流程。蓝色框中的编码就是用了熵编码。
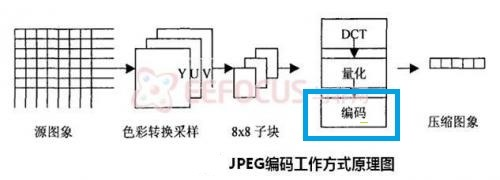
至于其他的视频标准,如MPEG2,H264, H265,编码流程都是大同小异,过程无非都是采样-DCT-量化-编码。它们都会用到熵编码,例如JPEG用的是Huffman编码和算术编码,H264用的是CAVLC和CABAC。
2.熵编码类型
2.1 CABAC
CABAC编码的目的是从概率的角度再做一次压缩,编码的过程主要分为二值化,上下文建模,二进制算术编码。
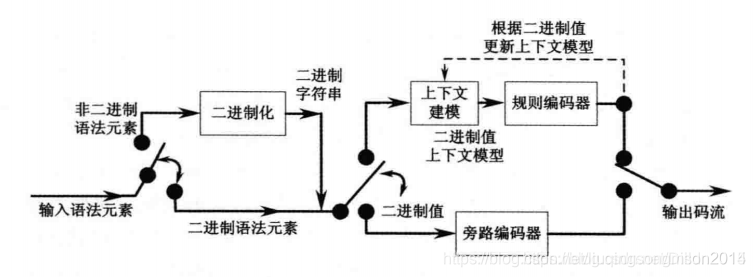
基于上下文的二进制算术编码(Context-Based Adaptive Binary Arithmetic Coding,CABAC)将自适应二进制算术编码和上下文模型相结合,是H.265/HEVC的主要熵编码方案。主要包括三个步骤:
1.二进制化;
2.上下文建模;
3.二进制算术编码;
其流程如下:
1.二值化
在图像处理世界中,所谓二值化就是将像素点的值根据一定的算法,将像素分别修改为0,或255,即获取图像的灰度图,或者通俗些讲就是图像的黑白图。而此处的“二值化”可以暂且理解为,将数值二进制化的一个过程,当然不是简单的将十进制转换为二进制。CABAC中二值化的方式主要有“一元码”,“截断一元码”,“K阶指数哥伦布编码”,“定长编码”,详细的就不展开了,不过小编决定了后续专门搞篇说这个的,嫑着急。这里简单以“一元码”简单举例说明下:
“一元码”的编码方式是,对于一个非二进制的无符号整数x >= 0,在CABAC中的一元码码字用x个“1”位外再加一个“0”组成。For example, 对“8”编码,则二值化后的结果为“111111110”。辣么,如果是6呢,你可以尝试一下的哦。
经过二值化之后,CABAC就已经把待编码的语法元素按照一定的规则转换为只用“0”和“1”的二进制流,称为比特流。
2.上下文编码
待编码数据具有上下文相关性,利用已编码数据提供的上下文信息,为待编码的数据选择合适的概率模型,这就是上下文建模。通过对上下文模型的构建,基本概率模型能够适应随视频图像而改变的统计特性,降低数据之间的冗余度,并减少运算开支。
H.264/AVC标准将一个Slice可能出现的数据划分为399个上下文模型,每个模型均有自己的上下文序号,命名为CtxIdx,每个不同的字符依据对应的上下文模型,来索引自身的概率查找表。即收到字符后,先找到字符对应的上下文模型的序号CtxIdx,然后根据CtxIdx找到其对应的概率查找表。 详细的步骤如下:
确定当前的字符对应的上下文模型的区间,H264标准中的表9-1描述了相应的对应关系。

按照不同的法则,在(1)步中得到的区间中最终确定的上下文模型个的CtxIdx。具体的法则同样需要去查找标准里对应的一些表,在此就不再赘述。
3.二进制算术编码
第三步通过上下文建模找到的概率模型的概率估计方法构成了一个自适应二进制算术编码器。概率估计是在前一次上下文建模阶段更新后的概率估计。在对每个二进制数值编码过后,概率估计的值相应的也会根据刚刚编码的二进制符号进行调整。
二进制算术编码是算术编码的特殊情况,其原理与一般算术编码一样(关于算术编码,大家可自行查阅,当然,小编也准备单开一篇缕缕喽)。不同的是,二进制算术编码序列只有“0”和“1”两种符号,所涉及的概率也只有P(0)和P(1)。
经过上述的步骤,同样也就经历了一次熵编码的完整过程,即CABAC的大概流程,由于细节部分涉及的内容相对较多,后续慢慢研究喽。希望对大家有所帮助哦。

